Czy sztuczna inteligencja jest inteligentna?
Kontakt w sprawie artykułu: Mateusz Pierzchała - 2023-07-31

To jeden z najmodniejszych dziś tematów: sztuczna inteligencja. Jest o niej bardzo głośno nie tylko w mediach branżowych, ale też i tych popularnych. Z jednej strony roztaczane są czarne wizje: że komputery najpierw pozbawią nas pracy, a potem przejmą władzę nad światem. Z drugiej strony media technologiczne prześcigają się w euforycznych zapowiedziach kolejnych zastosowań sztucznej inteligencji, która już teraz może wszystko, a będzie potrafiła jeszcze więcej.
Ponad 10 lat temu w felietonie na łamach Biuletynu Automatyki napisałem tak:
Jakie jest jedyne w języku polskim słowo, które zawiera aż pięć samogłosek „y”, a ponadto zaczyna się na „y” i kończy również na „y”? Chodzi rzecz jasna o przymiotnik „yntylygyntny”. Ta stara zagadka przypomina mi się zawsze, gdy czytam o jakiejś nowej formie inteligencji występującej na Ziemi. Bo niedługo wszystko będzie „inteligentne”, nawet płot albo łopata. Dziś mamy już inteligentne telefony, telewizory, lodówki, a nawet całe domy. Niedługo równie inteligentne będą samochody. W kolejce po inteligencję stoją miasta.
To miał być taki żart. Tymczasem po 10 latach rzeczywistość prześcignęła wyobrażenia – i faktycznie sztuczna inteligencja staje się wszechobecna. Potrafi z nami rozmawiać, potrafi narysować obrazek (jak można się przekonać poniżej), potrafi redagować teksty. Na łamach Biuletynu Automatyki i Poradnika Automatyka ukazują się informacje o bardzo ciekawych (i przynoszących wymierne korzyści!) zastosowaniach tej technologii w przemyśle. Czy komputery faktycznie niedługo zastąpią ludzi? Czy faktycznie sztuczna inteligencja potrafi wszystko? I jak to w ogóle jest możliwe?
A może faktycznie powinniśmy się obawiać? W dalszej części felietonu sprzed 10 lat napisałem:
IQ świata nieożywionego rośnie, ale mnie nieustannie trapi obawa, że wszystko mądrzeje – a ludzie głupieją.
Gdzie jest człowiek w tym wszystkim?
W Biuletynie Automatyki i na Poradniku Automatyka mocno stąpamy po ziemi i nie dajemy się ponieść emocjom. Postanowiliśmy poprosić ekspertów, aby wyjaśnili nam, czym jest ta mityczna sztuczna inteligencja, jak działa i co naprawdę potrafi. Opowiedzą o tym Szymon Rewilak i Mateusz Wojtulewicz z Zespołu AI w firmie ASTOR, którzy uczestniczyli m.in. we wdrożeniu Barometru AVEVA oraz w implementacji AI w systemie BMS w ASTOR Technology Park.
Mateusz Pierzchała: Czy wszyscy stracimy pracę przez ChatGPT?
Szymon Rewilak: Na razie na szczęście nie słyszy się o masowych zwolnieniach.
Media głoszą taką wizję, że przez sztuczną inteligencję wielu ludzi straci zajęcie. ChatGPT zastąpi autorów tekstów, programistów, doradców, nauczycieli. Ale jednocześnie – mam wrażenie – że nie bardzo potrafią nam wytłumaczyć, czym w ogóle sztuczna inteligencja jest.
Mateusz Wojtulewicz: Na ten temat jest bardzo dużo nieporozumień i błędnych opinii. A żeby zdefiniować, czym jest sztuczna inteligencja, trzeba byłoby sobie najpierw powiedzieć, czym jest inteligencja sama w sobie. I tu napotykamy na pierwszy problem, bo nie ma jednej, ogólnie przyjętej definicji tego pojęcia, a co za tym idzie – nie ma jednej definicji sztucznej inteligencji. Są dwa główne podejścia: techniczne oraz takie bardziej teoretyczne. Ja bardzo lubię tę techniczną definicję: sztuczna inteligencja to jest każdy system, który ma za zadanie imitować inteligencję naturalną, ludzką. Czyli wykonywać powierzone mu zadania w sposób zakładający pewną inteligencję. To jest bardzo ciekawa definicja, bo jest ona bardzo pojemna. Pasują do niej wszystkie proste algorytmy typu IF-ELSE, które na podstawie jakichkolwiek warunków podejmują proste decyzje. Tego typu algorytmy są ściśle zaprogramowane przez człowieka, więc nie można powiedzieć, że są „inteligentne same w sobie” albo że same się uczą. Jak widać, sztuczna inteligencja jest pojęciem naprawdę bardzo szerokim.
Bardziej teoretyczne podejście jest takie: inteligencja to jest miara umiejętności podmiotu do adaptacji do nowego zadania, w zależności od aktualnej wiedzy posiadanej przez ten podmiot, od trudności tego zadania oraz stopnia jego abstrakcyjności – w porównaniu do innych zadań, które podmiot potrafi wykonywać. Shane Legg i Marcus Hutter w swojej pracy „Universal Intelligence: A Definition of Machine Intelligence” podsumowali to jednym zdaniem: „Inteligencja mierzy zdolność do osiągania celów w rozmaitych środowiskach”. Jeszcze prościej można powiedzieć tak: inteligencja jest miarą umiejętności abstrakcji.
Ta definicja wywołuje pewne emocje wśród naukowców, którzy uważają, że sztuczna inteligencja wykonuje zadania, do których człowiek potrzebuje inteligencji, ale de facto bez używania inteligencji. Sztuczna inteligencja modeluje albo oblicza pewne rzeczy, przelicza pewne procesy, natomiast tak naprawdę nie ma inteligencji w rozumieniu ludzkim. Nie jest inteligentna, jest sztuczna.
Szymon: Powszechne wyobrażenie jest takie, że sztuczna inteligencja to jest taki „system”, który potrafi na podstawie danych wejściowych podejmować decyzje. To mocne uogólnienie. Jak powiedział Mateusz, definicja AI jest bardzo szeroka. Natomiast to, co mamy najczęściej na myśli, gdy mówimy o sztucznej inteligencji, to tak zwane uczenie maszynowe. Są to wszystkie algorytmy, które potrafią same się uczyć. Potrafią na podstawie doświadczenia „ulepszać się”. Możemy jednak pójść jeszcze głębiej – mamy też tzw. uczenie głębokie, które jest podzbiorem uczenia maszynowego. W tym przypadku nie podajemy systemowi żadnych cech, a więc tego, na podstawie czego ma podejmować decyzje. Dajemy mu tylko cel, przygotowujemy dane, a system sam się uczy, bez cech zadanych przez człowieka. Sam znajduje te cechy.
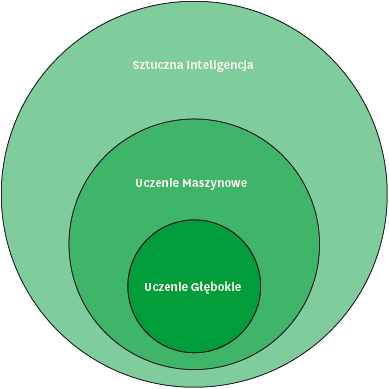
Tu warto jeszcze zwrócić uwagę na pewne częste nieporozumienie. Otóż dość popularna jest opinia, że sztuczna inteligencja to są systemy bardzo rozbudowane i o niemal cudownych możliwościach. Prawda jest taka, że czasami nawet bardzo banalne rozwiązanie, realizujące proste zadania, też już – w myśl definicji – możemy nazwać sztuczną inteligencją. A proste algorytmy uczenia maszynowego wcale nie są technicznie bardzo skomplikowane.
Ale mityczny ChatGPT jest jednak chyba dość skomplikowany?
Mateusz: ChatGPT jest systemem, który umieścilibyśmy na granicy między uczeniem maszynowym, a uczeniem głębokim – raczej bliżej uczenia głębokiego. Gwoli ścisłości pamiętajmy, chat to jest prosty chatbot, prosta aplikacja internetowa. Tak naprawdę całą pracę wykonuje model GPT (obecnie już w wersji 4), który jest podstawą działania tego systemu. Jest to model oparty na tzw. transformerach, czyli sieciach neuronowych o architekturze przystosowanej pod zadania przetwarzania języka naturalnego. Był on wytrenowany na ogromnym korpusie około 45 TB danych wejściowych. Na te dane składały się m.in. Wikipedia, miliony artykułów naukowych i nienaukowych, blogi, książki, właściwie wszystko, co jest w Internecie. W efekcie wytrenowany został model językowy przystosowany do zadania przewidywania kolejnych wyrazów w tekście (sequence completion). Następnie dotrenowano model GPT3 przy pomocy dodatkowych 570GB danych tekstowych, przygotowanych pod kątem przygotowania chatbota. Na podstawie tych wszystkich danych model został wytrenowany, czyli została zbudowana pewna baza językowa, model językowy, a na podstawie tego modelu zostały stworzone aplikacje takie, jak ChatGPT, który generuje odpowiedzi na pytania.
Mamy więc do czynienia z modelem, który – jak w starym kawale – jest jak Chuck Norris: przeczytał cały Internet?
Mateusz: dobre porównanie, ale niepełne. Gdyby przeczytał cały Internet, to byłby klasyczny przypadek przetrenowania. Przetrenowanie to jest – w uproszczeniu mówiąc – taki stan systemu, kiedy „nauczył się” on czegoś na pamięć, czyli de facto nie zgeneralizował tego, czego się uczył, nie stworzył pewnego modelu, nauczył się po prostu wszystkiego na pamięć. Można posłużyć się prostym przykładem: mam dobrą pamięć, więc nauczę się tabliczki mnożenia do 100, czyli maksymalnie do działania 10 x 10, ale bez zrozumienia procesu mnożenia. Gdy ktoś mnie zapyta, ile jest 5 x 5, to będę wiedzieć, ale jak mnie ktoś zapyta, ile jest 5 x 100, to nie będę umiał tego policzyć.
Czyli można w uproszczeniu powiedzieć: nauczył się, ale nie zrozumiał?
Mateusz: Tak. Coś takiego zdarza się zazwyczaj wtedy, kiedy model jest zbyt pojemny w stosunku do stopnia skomplikowania zadania.
Szymon: Innymi słowami można powiedzieć, że opisuje zbyt wiele parametrów w stosunku do ilości danych, na których jest uczony.
Zatem wiemy już, że nie wystarczy, by sztuczna inteligencja przeczytała Internet. Musi jeszcze potrenować?
Szymon: Oczywiście – i zwykle trenowanie modelu to nie jest jednorazowa operacja. Tutaj trzeba powiedzieć, że modele takie, jak GPT zmagają się z dwoma wymaganiami: żeby zamodelować język oraz żeby pisać w sposób zrozumiały dla ludzi. Tego rodzaju model językowy możemy porównać do ogromnie skomplikowanej funkcji o milionach parametrów. Jest to model generatywny, co rozumiemy w taki sposób, że ta skomplikowana funkcja przyjmuje pewne dane wejściowe i przetwarza je w taki sposób, że na wyjściu wyprowadza pewne dane wyjściowe. Aby tak było, trzeba ją tego nauczyć. W przypadku GPT proces miał kilka etapów. Model był uczony w taki sposób, żeby jego język był jak najbardziej zrozumiały i jak najbardziej podobny do człowieka. By to osiągnąć, najpierw sam się uczył – na podstawie dostarczonych mu danych – a następnie był poddawany douczeniu. A to już był proces z udziałem ludzi. Zatrudnieni zostali tzw. tutorzy, którzy rozmawiali z czatem i zadawali mu pytania. Na każde pytanie model przygotowywał pięć odpowiedzi, a tutorzy oceniali je, układając w kolejności od najlepszej do najgorszej. Ta swego rodzaju informacja zwrotna była przez model wykorzystana do ulepszenia swojego działania.
Mateusz: Pamiętajmy też, że łatwo się mówi: model. Informatycznie jest to bardzo złożony system, składający się z wielu skomplikowanych algorytmów. Jest w GPT na przykład zaszyty bardzo ciekawy mechanizm atencji, który pozwala na utrzymywanie kontekstu. Chodzi o to, że ChatGPT „pamięta”, co mówił przed chwilą. Pamięta na przykład, co było podmiotem w zdaniu i potrafi do tego dopasować formę orzeczenia. Dzięki temu wypowiedzi są generalnie spójne.
Mamy więc model, który odpowiada na pytania, pisze artykuły, programy lub wiersze. Copywriterzy i programiści boją się o miejsca pracy. Amazon wstrzymał nawet wydawanie nowych autorów w ramach self-publishingu, gdyż ponoć zalała go fala „literatury” wygenerowanej przez ChatGPT. Ale czy to naprawdę jest twórczość? Na czym polega kreatywność takiego modelu?
Mateusz: Jeżeli model GPT wygeneruje pewne zdania, to są to zdania, które on rzeczywiście wygenerował. Nie jest tak, że są to zdania napisane przez ludzi, które model „skopiował” z Internetu. Nie jest tak, że on znajduje gotowe wypowiedzi w swojej bazie, ponieważ tam po prostu nie ma bazy wiedzy. Jest tam tylko model języka. On nie patrzy na dane, z których się uczył, tylko na to, co wyszło z tych danych – i na tej podstawie generuje kolejne słowa i kolejne zdania. Jest to więc jakiś rodzaj kreatywności, sztucznej kreatywności. Ale ten model nauczył się umiejętności tworzenia zdań na podstawie tekstów, które ktoś faktycznie napisał lub powiedział. Jest to model stochastyczny, a więc w pewnej mierze losowy. Nie można więc wykluczyć, że wygeneruje zdanie identyczne jak to, które ktoś kiedyś faktycznie napisał. Ewentualnych posądzeń o plagiat bym nie wykluczał.
Szymon: Popatrzmy na GPT jak na taki symulator, który może imitować, co ludzie „by powiedzieli” w odpowiedzi na dane pytanie. Symulator ten uczył się, czytając miliardy zdań prawdziwych ludzi. Można to porównać do dziecka, które od urodzenia słuchało swoich rodziców, którzy używali pewnych sformułowań, niektórych zbyt często, a potem dziecko to powtarza. Czasem dosłownie, czasem kreatywnie, a czasem zabawnie przekręcając.
A jak się to ma do pisania kodu programistycznego?
Mateusz: Cóż, to jest ten sam model. GPT rozumie język programowania tak, jak każdy język naturalny. Pamiętajmy, że języki programowania są dużo, dużo prostsze od naturalnych. Model „uczy się” ich przez czytanie kodu. Programiści jednak prędko nie stracą pracy, przynajmniej nie wszyscy. GPT potrafi rozwiązywać bardzo proste zadania. Takie w rodzaju przysłowiowych 10 linijek kodu, rozwiązujących jakiś prosty problem. Ale to jest wiedza, która i bez GPT jest obecnie dostępna dla każdego – i programiści zawsze z niej korzystali. Jeżeli ktoś potrafi dobrze korzystać z Google, poradzi sobie bez ChatGPT. Natomiast już bardziej złożone problemy programistyczne są poza zasięgiem takiego modelu w tej chwili. Albo odpowie nam bardzo ogólnie i powie coś, co nie ma żadnej treści, albo przedstawi błędne rozwiązanie. Bez trudu znaleźliśmy kiedyś bardzo prosty problem programistyczny, którego ChatGPT nie potrafił rozwiązać. W pewnych sytuacjach rozwiązanie to może nam pomóc, jednak wciąż ma bardzo poważne ograniczenia.

Poruszyliśmy w ten sposób poważniejszy temat: czy to, co pisze nam sztuczna inteligencja, jest w ogóle wiarygodne?
Szymon: Na swojej stronie firma Open AI (autor ChatGPT) jasno komunikuje, że ich model ma istotne ograniczenia i nie może być traktowany jako „źródło prawdy”. Z pewnością na razie nie są to rozwiązania w pełni wiarygodne. Porównałbym ChatGPT do kogoś, kto jest bardzo zadufany w swoją wiedzę i nigdy nie przyzna się, że czegoś nie wie. Czasami mówi więc autorytatywnie: proszę bardzo, to jest prawda – a tak naprawdę wcale nie jest to prawda. Jest więc jak taki anegdotyczny wujek na imprezie, który wypowiada się na każdy temat na świecie, bez cienia wątpliwości i nie znosząc sprzeciwu.
Mówi się o takich ludziach: „najmądrzejszy z całej wsi”. Albo „głupio-mądry”.
Szymon: ChatGPT w jednej z poprzednich wersji uparcie przekonywał użytkowników, że kilogram gwoździ jest cięższy niż kilogram pierza. Bo tak mu się wydawało. Mamy więc model zbudowany na podstawie ogromnej bazy wiedzy, ale nie można go nazwać „źródłem prawdy”. Dlatego nadal samodzielne poszukiwanie i czytanie informacji jest wiarygodniejsze od jakiegokolwiek modelu AI.
Powiedziałeś jednak: „na razie”. Czy na razie nie, ale kiedyś tak?
Szymon: Model wie tyle, jakie ma dane. Musiałby być znacznie bardziej rozbudowany i mieć w pełni wiarygodne dane, wtedy to będzie możliwe. Jest jednak inna, bardzo ważna rzecz, o której warto wspomnieć. Tym, na czym świat Data Science jest obecnie najbardziej skupiony, jest wyjaśnialność (ang. explainibility). Bardzo często mamy do czynienia z sytuacją, że z takiego czarnego pudełka sztucznej inteligencji dostajemy wynik, ale chcielibyśmy wiedzieć, dlaczego wynik jest taki, a nie inny. Z taką sytuacją mamy do czynienia w wielu odpowiedzialnych zastosowaniach, na przykład w przypadku systemów medycznych. Chcemy wiedzieć, dlaczego system podał taki wynik, ponieważ mamy do czynienia z bardzo dużym ryzykiem. Ma to też wpływ przy wyborze algorytmu, bo czasami potrzebujemy mieć większą wyjaśnialność, nawet kosztem innych parametrów. Nad rozwojem w tej dziedzinie obecnie bardzo intensywnie się pracuje.
Gdy widzę w mediach te wszystkie euforyczne nagłówki, dziwi mnie jeszcze jedno. Mam już swoje lata i dlatego świetnie pamiętam, że to wszystko, o czym mówimy, to nie jest żadna nowość. O sztucznej inteligencji czy sieciach neuronowych była mowa już w latach 80. ubiegłego wieku. Skąd dziś ta eksplozja zainteresowania tematem?
Mateusz: Oczywiście to nie jest nowość. Teoretyczne podstawy sztucznej inteligencji zostały wymyślone wiele lat temu. Natomiast wtedy nie byliśmy gotowi technicznie na ich zastosowanie. Ciekawostka: niektóre algorytmy (jak na przykład wnioskowanie Bayesowskie) istniały długo przed komputerami i były wyprowadzone i obliczane na kartkach. Dziś mamy dużo większe moce obliczeniowe i dużo większe możliwości przechowywania i przetwarzania danych. Zebrać i przechowywać taką ilość danych jest bardzo trudno, nie mówiąc już o tym, jaki czas jest potrzebny do ich przetworzenia. Te algorytmy, które kiedyś ludzie wymyślili, teraz znajdują zastosowanie do rozwiązywania problemów nieraz bardzo przyziemnych, które zawsze występowały, ale nie było takiej potrzeby, żeby je aż tak optymalizować. Fabryka nie potrzebuje optymalizacji robotów, jeżeli nie ma robotów. Teraz mamy roboty, mamy skomplikowane systemy sterowania, SCADA, mamy różne inne rozwiązania, więc do tego możemy dołożyć sztuczną inteligencję i znaleźć oszczędności o 1, 5 lub 8%.
Szymon: Poza tym dużo się dziś mówi o sztucznej inteligencji, ponieważ teraz ma to wartość. Dziś mamy z tego oszczędności, mamy konkretne zyski. Z naukowego punktu widzenia nie mamy teraz do czynienia z jakimś niesamowitym rozwojem sztucznej inteligencji. Nie są to żadne nowe kamienie milowe. Rozwój oczywiście następuje, ale głównie w obszarach, które są mało medialne (np. wspominana wyjaśnialność). Natomiast z perspektywy praktycznej, z punktu widzenia naszego patrzenia, rozwój jest dziś bardzo duży, ponieważ dopiero teraz możemy zastosować w praktyce rozwiązania wymyślone dawno temu – i powstają takie efektowne narzędzia, jak ChatGPT czy Midjourney.
Porozmawiajmy chwilę o tych rozwiązaniach. W powszechnym odbiorze często spotyka się takie uproszczenie, że sztuczna inteligencja równa się sieci neuronowe. Bardzo tego nie lubicie.
Mateusz: Utożsamianie sztucznej inteligencji z sieciami neuronowymi jest bardzo dużym błędem. Istnieją dziesiątki algorytmów AI, dużo prostszych i dużo częściej w rzeczywistości wykorzystywanych, jak choćby algorytmy regresji liniowej czy drzewa decyzyjne. Na ogół te algorytmy poradzą sobie znacznie lepiej, niż sieci neuronowe. Sieć neuronowa jest często armatą na wróbla. Będzie zbyt skomplikowana albo się po prostu przeuczy.
Szymon: Naszym zdaniem sieć neuronowa nie jest algorytmem, lecz raczej systemem obliczeniowym. Algorytmem jest na przykład samouczenie sieci. Prawda jest jednak taka, że jeżeli nie mamy pomysłu, jak skonstruować system sztucznej inteligencji, zazwyczaj w pierwszej kolejności sięgamy po algorytmy drzewiaste. Myślę, że sieć neuronowa jest tak popularna, bo ta nazwa po prostu dobrze brzmi. Kojarzy się z mózgiem, sztucznym mózgiem.
Mateusz: Żeby było jasne: sieci neuronowe jest to doskonały mechanizm, który sprawdza się w wielu sytuacjach, ponieważ jest bardzo szeroka rodzina funkcji, którą sieci neuronowe są w stanie przybliżyć. Nazywa się je uniwersalnymi aproksymatorami funkcji. Bo w sztucznej inteligencji chodzi zawsze o to, że poszukujemy pewnej funkcji opisującej rzeczywistość, a nie zawsze ta funkcja jest dostępna wprost. Potrzebne jest znalezienie jakiegoś jej przybliżenia. Sieć neuronowa jest w tym doskonała, ma bardzo dużo parametrów, jest plastyczna w dostrajaniu się do pewnych okoliczności. Dlatego tak często stosuje się sieci, szczególnie w wielowymiarowych i skomplikowanych problemach.
Co jest dziś największym wyzwaniem dla praktycznego wykorzystywania sztucznej inteligencji?
Szymon: Najbardziej prozaiczne wyzwania to moc obliczeniowa i dostępne dane. W jednym ze studenckich projektów natknąłem się np. na taki problem, że obrazy, które musiałem przetwarzać, były tak duże, że nie miałem dostępu do takiej karty graficznej, która by temu podołała. Jeżeli zaś chodzi o dane, to problemem może być mała wiedza o danym zjawisku. Trzeba mieć dużą wiedzę o zjawisku, żeby je dobrze zamodelować. Jako data scientist muszę znać dobrze proces, który obrabiam. Muszę odpowiednio dobrać cechy dla algorytmu uczenia maszynowego. Jeżeli mamy za dużo cech – mamy przeuczenie. Jeżeli weźmiemy za mało parametrów, sieć będzie za słabo wytrenowana.
Kolejne wyzwanie to właściwy dobór narzędzia. Jak wspomniał Mateusz, mamy bardzo dużo algorytmów i musimy je właściwie dobrać do zastosowania: czy bierzemy sieci neuronowe, czy bierzemy drzewa decyzyjne, itd. Trzeba tu też wziąć pod uwagę, że niektóre rozwiązania są bardziej kosztowne od innych, na przykład ze względu na potrzebną moc obliczeniową. Trzeba to analizować pod kątem korzyści biznesowych.
Co ciekawe kolejnym wyzwaniem jest stochastyczność modeli. Niektóre modele są stochastyczne, to znaczy nie są deterministyczne, a więc mogą dawać różne wyniki dla takich samych danych wejściowych. W pewnych sytuacjach to może być problem.
Klaruje się tu bardzo jasny obraz. Algorytm jest ważny, ale najważniejsze są dane.
Mateusz: W świecie Data Science jest bardzo znane powiedzenie: jeżeli masz śmieci na wejściu, dostajesz śmieci na wyjściu. Dane zawsze trzeba przygotować. Nawet zwykłe wrzucenie do bazy danych jest już pewnym rodzajem przygotowania. Dane muszą być rzetelne i – jak już wspominaliśmy – jak najlepiej opisywać modelowane zjawisko. Jedna rzecz jest ważna. Wbrew temu, czego można byłoby się obawiać, pojedyncze błędy w danych nie stanowią poważnego problemu, podobnie jak występowanie rozbieżności. W dużym uproszczeniu można powiedzieć, że modele sztucznej inteligencji zawsze dokonują pewnych uśrednień. Przykładowo jeżeli w danych znajdzie się informacja, że średni wzrost ludzi na świecie to 175 cm, a w innym miejscu – że 180 cm, to model się od tego nie zawiesi, nie wybierze też żadnej z tych wartości, tylko dokona pewnego uśrednienia.
Można powiedzieć: pojedynczy błąd nie ma znaczenia, ⅓ danych ma znaczenie?
Mateusz: Tak. Jeżeli jedna trzecia danych w zbiorze będzie nierzetelna, to uzyskane wyniki na pewno nie będą wiarygodne. Dobór danych w dużym przekroju ma bezpośredni wpływ na wyniki. Z przymrużeniem oka można podać prosty przykład ze świata polityki: jak z danych usuniemy treści prawicowe, to otrzymamy model lewicowy – i odwrotnie. Dane muszą więc być reprezentatywne.
Dlaczego sztuczna inteligencja to takie skuteczne narzędzie w zastosowaniach przemysłowych?
Mateusz: W przemyśle jest bardzo duży potencjał optymalizacji dzięki sztucznej inteligencji. Optymalizacja to jest słowo kluczowe. Dlatego właśnie korzystamy z takich technologii. Poszukujemy oszczędności, poszukujemy ulepszeń – i te algorytmy mogą w tym bardzo pomóc. Przede wszystkim dlatego, że w przemyśle zwykle jest ogrom danych. Jest w nich dużo informacji, dużo wiedzy, która aż się prosi, żeby ją wykorzystać – natomiast nie widać jej gołym okiem. Oczywiście te dane są specyficzne. Jest ich bardzo dużo, zwykle są bardzo surowe i napływają z dużą częstotliwością, ale są takie algorytmy, które sobie z tego rodzaju danymi bardzo dobrze radzą. Ważne jednak, aby dobrze określić, jaki jest cel zastosowania takiego algorytmu, co konkretnie chcemy osiągnąć. Czy optymalizować? Czy przewidzieć awarię?
Szymon: Nawet proste, eksperymentalne systemy, takie jak Barometr AVEVA albo system optymalizujący pracę windy w budynku ASTOR Technology Park, pokazują że dla sztucznej inteligencji właściwie nie ma ograniczeń. Czyli jakiegokolwiek problemu byśmy nie sformułowali, sztuczna inteligencja będzie się do tego nadawać. W przemyśle ma to szczególne znaczenie. Wyobraźmy sobie, że mamy do czynienia z prostą w sumie sytuacją, w której jest kilkanaście sygnałów, które musimy wysterować. Możliwych kombinacji ustawień tych sygnałów może być kilkanaście milionów. Przygotować funkcję, która będzie to regulować lub optymalizować jest bardzo trudno. Tymczasem algorytmy sztucznej inteligencji potrafią sobie radzić z tego rodzaju wyzwaniami.

A po co sztuczna inteligencja w Wordzie? Czy inteligentne automaty, które we wszystkim zaczynają nas wyręczać, nie doprowadzą w końcu do naszego całkowitego ogłupienia? Wszak mówi się, że nieużywany organ zanika.
Mateusz: To jest bardzo humanistyczne pytanie. Kwestią nie jest to, czy sztuczna inteligencja jest gdzieś potrzebna, tylko czy ktoś jej tam chce. Jeżeli ktoś znajdzie w tym biznes, a ktoś inny będzie chciał za to zapłacić, to będzie to zrobione. To jest pytanie o każdy rodzaj innowacyjności. Czy jest potrzebna automatyzacja, robotyzacja? Na przykład mamy skiturowców, którzy podjeżdżają na nartach na samą górę, i mamy tych, którzy korzystają z wyciągów. Możemy zawsze powiedzieć, że jakiś mechanizm nie jest potrzebny, że nie jest to rzecz, bez której ludzie nie mogliby żyć, ale jest on przydatny – i ktoś jest w stanie za to zapłacić.
A co z tymi masowymi zwolnieniami? Stracimy pracę, czy nie?
Szymon: Jeżeli praca jest bardzo mocno powtarzalna, może być zastąpiona przez maszyny i algorytmy. Technologia od zawsze zabiera pracę. Ale czynnik humanistyczny jest bardzo ważny. Zwykle wolimy zobaczyć prawdziwego, żywego człowieka, niż system albo komputer. Nie ma się też co obawiać, że pracę stracą artyści. Jeżeli mamy taką potrzebę, że potrzebujemy obrazu zachodzącego słońca, to wpisujemy to w Google albo do którejś z powstających aplikacji generujących obrazy – i mamy obraz zachodzącego słońca. Ale to nie to samo, co prawdziwy obraz namalowany przez malarza. To jest ta sama sytuacja, z którą mieliśmy do czynienia sto lat temu: gdy byłem malarzem, to brali mnie na Antarktydę, żeby namalować tamtejszy pejzaż, a teraz pojawia się magiczne pudełko, w którym wystarczy nacisnąć przycisk i obraz już jest. Mowa o aparacie fotograficznym. To była ta sama obawa. Ale potem zostało to zaakceptowane i teraz fotografia jest dziedziną sztuki kropka. Więc w Google mogę znajdować nie tylko gotowe obrazy, ale wciąż mogę znajdować artystów.
Mateusz: Czynnik ludzki zawsze będzie potrzebny. To jest w ogóle ciekawy problem: Czy istnieje coś takiego jak ogólna, wszystkowiedząca sztuczna inteligencja? Taka totalna? Być może coś takiego może istnieć, natomiast teraz jej nie ma. Jeżeli kiedyś będzie, to znaczy, że to na pewno człowiek będzie musiał ją stworzyć. Pewne jest jednak, że to jest jeszcze daleko, daleko przed nami.
rozmawiał: Mateusz Pierzchała



Super, wszystko wyjaśnione, spowrotem człowiekowi opadły emocje i widzi teraz. ile. tu jest ludzkiej pracy, aby to cała ta sztuczna inteligencja działała.
a czy ma ktoś strone podobną jak asystent google ale inna sztuczna inteligenja no hcyba że ta sama