Katarzyna Pakulska 2019-07-08
Treści
Transformacja do Przemysłu 4.0 z Data Science w tle
Transformacja do Przemysłu 4.0 z Data Science w tle
Oto typowy scenariusz z życia: na linii produkcyjnej pracuje maszyna, która ma kluczowy udział w produkcji naszej firmy. Jeszcze nie wiemy, że jej awaria może przysporzyć olbrzymich problemów i niespodziewanych kosztów. Sprowadzenie lub zbudowanie nowej trwać będzie kilka tygodni. Czy tak musi się stać?
W sytuacjach kryzysowych nieraz zdarza nam się słyszeć słowa w stylu „gdybym wcześniej wiedział, że nastąpi taki problem, to bym …”. Dawniej tego typu akcje były nieprzewidywalne . Dziś to kwestia decyzji biznesowej czy chcemy i czy opłaca nam się przewidywać problemy. W tym artykule postaram się przedstawić jak rozpocząć taką drogę i z czym ona się wiąże.
Na początek okno zdarzeń

To na podstawie archiwalnych danych, jakie jest typowe okno danych i parametrów dla poprawnie działającego systemu. Wszelkie anomalie mogą skutkować awarią i powinny być wcześniej zgłaszane obsłudze. W ten sposób obsługa może serwisować maszynę w celu przeglądu, co pozwoli na szybką naprawę maszyny przed bezpośrednią lub czasem nieodwracalną awarią. W poniższych punktach postaramy się objaśnić krótko każdy z kroków zaproponowanej piramidy akcji.
Piramida akcji – jak zbudować swoją?
Wszystko zaczyna się od gromadzenia danych. Nie ma znaczenia w jakiej formie – ważna jest świadomość, że dzięki danym archiwalnym, bedziemy przewidzieć kiedy maszyna zachowuje się inaczej, niż na co dzień. Piramida akcji w każdej firmie może wyglądać inaczej, w zalezności od stopnia automatyzacji procesów produkcyjnych.
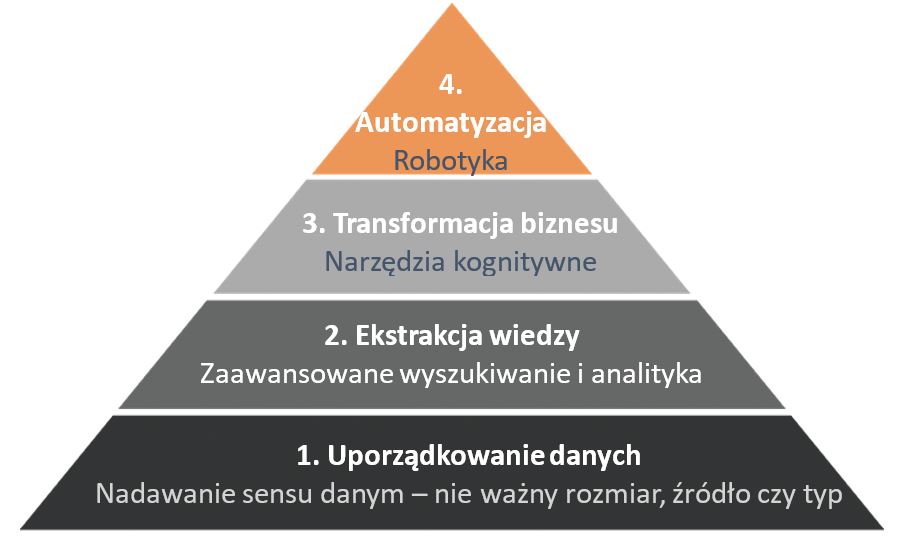
1. Uporządkowanie danych
Gromadzenie danych z różnych źródeł i różnego typu to bardzo ważny i podstawowy krok, jednak takie dane są często niespójne, zawierające różne błędy lub czasem są po prostu zbyt duże do przetworzenia. Problemów, które mogą udaremnić analizę danych na tak zwanych „surowych danych” jest bardzo wiele, na przykład:
- Wartości brakujące: brak określonych atrybutów lub ich wartości;
- Szum: zawiera błędy lub wartości odstające, które odbiegają od oczekiwanych;
- Niespójności: zachowanie rozbieżności w odniesieniach do atrybutów lub używanie różnych jednostek miary;
- Integracja danych: w jaki sposób możemy mieć pewność, że identyfikator klienta w jednej bazie danych odnosi się do tego samego numeru w polu o zbliżonej nazwie w drugiej bazie danych.
- Redukcja danych: pomaga w uzyskaniu wysokiej jakości wiedzy bez naruszania integralności danych pierwotnych, itp.
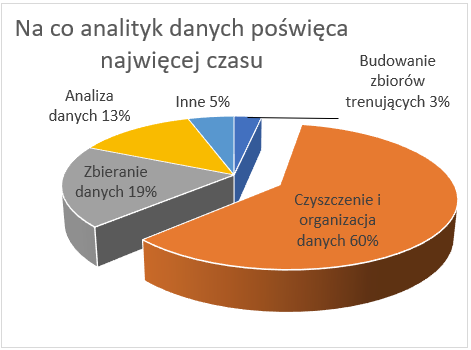
( Produkt z materiałów złej jakości też będzie złej jakości ang. „Garbage in, garbage out” GIGO). W dziedzinie informatyki lub technologii informacyjno-komunikacyjnej oznacza to, że komputery działając w oparciu o procesy logiczne, będą bezwarunkowo przetwarzać niezamierzone (nawet bezsensowne) dane wejściowe, na bazie których stworzą niepożądane, często absurdalne wyniki. Zasadę tę można z sukcesem odnieść do technik analizy danych. W przypadku zastosowania nawet najlepszych algorytmów z dziedziny analizy na nieuporządkowanych danych, otrzymamy miernej jakości modele i wzorce. Aby tego uniknąć, surowe dane są poddawane wstępnej analizie z uwzględnieniem wydajności oraz specyfiki metody ekstraktującej wiedzę. Jest to bardzo ważny i pracochłonny proces, może on zajmować nawet powyżej 60% czasu przeznaczonego na pełną analizę danych.
2. Ekstrakcja wiedzy – magia dzięki sieciom neuronowym
Jak niektórzy przywykli mówić „tu dzieje się cała magia”. Oznacza to, że w tym kroku budujemy modele predykcyjne, czy uczymy sieci neuronowe, które pomogą nam w analizie problemu. Technik i algorytmów tu zastosowanych może być mnóstwo i nadają się na oddzielną serię artykułów. Dlatego wyszczególnimy tu bardzo ogólne 2 typy algorytmów: nadzorowane i nienadzorowane.
Uczenie nadzorowane jest tak nazywane, ponieważ wymaga „nauczyciela”, który pokaże jak klasyfikować dane. Oznacza to, że wcześniej mamy wiedzę na temat wartości wyjściowych dla naszych próbek. Celem nadzorowanego uczenia się jest poznanie funkcji, która biorąc pod uwagę próbkę danych i pożądane wyniki, najlepiej przybliża związek między danymi wejściowymi i wyjściowymi możliwymi do zaobserwowania w danych. W tym przypadku potrzebujemy nie tylko danych archiwalnych, ale także ich poprawnej klasyfikacji względem problemu.
Ten zbiór, nazywany trenującym, pozwoli nam nauczyć algorytm tak, aby potem sam mógł podejmować decyzję. Przykładami problemów, które zostały w ten sposób rozwiązane mogą być:
- Sortowanie śmieci: robot uczy się sortować śmieci za pomocą analizy obrazu. Wybiera on przedmioty nadające się do recyklingu, gdy przechodzą one przez przenośnik taśmowy. Umieszcza przedmioty takie jak szkło, plastik i metal w oddzielnych pojemnikach. Raz dziennie eksperci badają pojemniki i informują robota, które przedmioty zostały niewłaściwie posortowane.
- Przewidywanie wartości: maszyna jest szkolona do przewidywania miar takich jak cena lub jej wzrost. W ten sposób buduje się modele predykcyjne wartości domów/nieruchomości w danej okolicy lub przewiduje ceny na giełdzie.
Z kolei Nienadzorowane mechanizmy uczenia maszynowego wykorzystuje się do wykrywania nieznanych wcześniej wzorców w danych. Metoda ta jest najchętniej stosowana w przypadku braku danych na temat pożądanych rezultatów, takich jak określenie rynku docelowego dla zupełnie nowego produktu, którego firma nigdy wcześniej nie sprzedała. Innymi przykładami zastosowania mogą być:
- Wykrywanie anomalii: może automatycznie wykryć nietypowe punkty w zestawie danych. Jest to użyteczne przy wykrywaniu nieuczciwych transakcji, wykrywaniu wadliwych elementów sprzętu lub wykrywaniu odstępstwa spowodowanego przez błąd człowieka podczas wprowadzania danych.
- Analizy częstego koszyka: identyfikuje zestawy elementów, które często występują razem w zestawie danych. Detaliści często używają go do analizy koszy, ponieważ pozwala to analitykom odkryć towary często kupowane w tym samym czasie i opracować skuteczniejsze strategie marketingowe.
3. Transformacja biznesu
Są dwie drogi na poprawę wydajności firmy: zwiększanie przychodu i redukcja kosztów. Najważniejszą rzeczą jest znaleźć takie przypadki zastosowania ekstrakcji wiedzy, aby zmienić coś w biznesie. Aby to osiągać trzeba dokładnie określić i zakomunikować cel, który biznes chce osiągnąć.
A oto konkretny przykład – w jednym z naszych projektów w sektorze energetycznym problem dotyczył lokalizacji stacji ładowania samochodów elektrycznych. Do tej pory takie decyzje podejmował zespół ludzi, w którym każdy z jego pracowników analizował tylko fragment danych i inaczej je interpretował. Czym to skutkowało? Dużą liczbą spotkań owej grupy, które nie prowadziły do podjęcia żadnych decyzji. Tym samy proces ten angażował dużo osób i masę czasu, przez co stawał się bardzo kosztowny i nieefektywny.
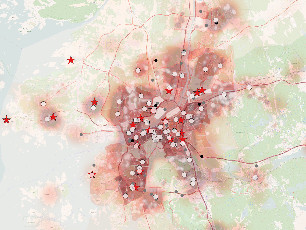
Proces ten został zmieniony przy użyciu analizy wiedzy. Nałożono na mapy gęstości zaludnienia, natężenia ruchu, danych dotyczących lokalizacji i eksploatacji poprzednich stacji energetycznych, itp. W wyniku tak powstałej mapy ciepła, możliwe było zidentyfikowanie strategicznych lokalizacji dla umieszczania nowych stacji ładowania. Zamiast wielokrotnych bezowocnych spotkań, powstała mapa, dzięki której nowe lokalizacje były wybierane szybciej i mniej osób musiało uczestniczyć w takich analizach. Analiza natomiast była bardziej obiektywna i uwzględniała więcej aspektów niż jej dotychczasowy ludzki odpowiednik.
4. Pełna automatyzacja
Jest to ostatni krok ku Przemysłowi 4.0. Obecnie niewiele firm się na taki decyduje. Nie wyklucza to jednak podjęcia kroków, które zbliżają nas do pełnej automatyzacji. Co więcej, taki proces może być rozłożony w czasie. Podobnie jak u jednego z naszych klientów- firmy zajmującej się odbiorem śmieci w mieście. Firma ta każdego roku automatyzowała część procesu. Na przykład monitorowaliśmy kierowców ciężarówek w ich codziennej pracy. Na podstawie tej wiedzy, wzbogaconej o dwuletnią historię odwiedzanych lokalizacji w połączeniu z danymi wagowymi ze stacji przeładunkowych, przeanalizowaliśmy i zwizualizowaliśmy, jak wykorzystano czas, w jaki sposób wykorzystano pojemność (ładunek) ciężarówki oraz w jaki sposób dokonywano załadunku i rozładunku na stacjach.
Dzięki tak przeprowadzonej analizie, możliwe było podjęcie kolejnych kroków ku pełnej automatyzacji, obejmujących między innymi:
- wyznaczenie nowych tras kierowców, które skutkowały rzadszą koniecznością wracania do stacji rozładunkowych i zwiększyły średni procent wypełnienia powracających do stacji ciężarówek;
- modyfikację godziny odbioru śmieci w poszczególnych miejscach tak, aby zminimalizować czas stania w korkach.
W kolejnych krokach można będzie analizować w czasie rzeczywistym przejezdność tras i modyfikować je w celu minimalizowania strat na stanie w korkach, czy objazdach. Zmiany te mogą być automatycznie udostępniane na tablecie kierowcy, w celu natychmiastowego dostosowywania tras do warunków na drogach.
Więcej przeczytasz w piśmie Biznes i Produkcja.


